RAG is a methodology that enhances the capabilities of large language models (LLMs) by integrating external knowledge sources into the generation process. By retrieving relevant information from knowledge bases or document collections, RAG enables LLMs to produce more accurate and contextually aware responses, mitigating the issue of hallucinations.
The process involves a two-stage approach: first, a retrieval mechanism extracts relevant information from knowledge bases or large document collections; then, a large language model (LLM) utilizes this retrieved information to generate a response, thereby enhancing the quality and accuracy of the output.
Basic RAG Pipeline
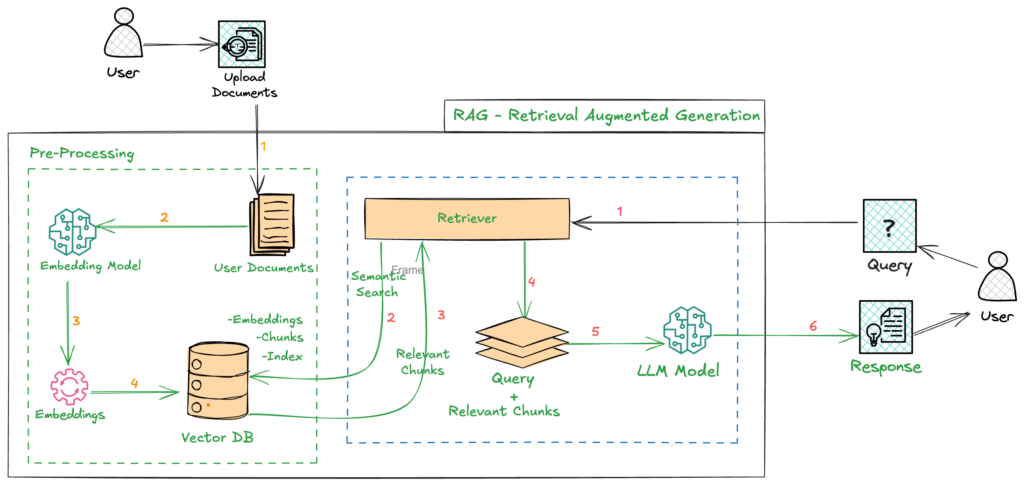
As show in the above picture, RAG has the following components
1.Pre-Processing(Indexing)
The indexing process is a complex offline step that begins with data cleaning and extraction. This involves converting various file formats into a standardized plain text format, which is then divided into smaller chunks through a process called chunking. These chunks are transformed into vector representations using specialized embedding models, and the resulting vectors are stored in an index as key-value pairs in vector stores. This indexing process allows for efficient and scalable search capabilities, enabling rapid retrieval of relevant information.
2.Retrieval
The user query is first processed by an encoding model, which generates a set of semantically related embeddings that capture the query’s meaning and context. These embeddings are then used to conduct a similarity search on a vector database, which stores a large collection of data objects. The search algorithm retrieves the top k data objects that are closest to the query embeddings, based on a similarity metric such as cosine similarity or Euclidean distance
3.Generation
The user query and the retrieved additional context are filled into a prompt template. Finally, the augmented prompt from the retrieval step is input into the LLM
However, Basic RAG systems face critical challenges, including low retrieval accuracy, a lack of contextual awareness in responses, and difficulties in addressing multifaceted queries, which limit their effectiveness. To overcome these limitations, advanced RAG techniques are necessary to enhance response accuracy and reliability, enabling AI systems to dynamically update their knowledge bases and provide users with the most current information. This adaptability is essential in rapidly evolving domains, where real-time data is crucial for meeting user expectations for timely and precise answers, making advanced RAG techniques a vital component in improving the overall performance and user experience of AI systems.

Advanced RAG
Advanced RAG has emerged as a new approach, building upon the Basic RAG paradigm with targeted improvements. The optimization techniques used in Advanced RAG can be grouped into three main categories: pre-retrieval, retrieval, and post-retrieval optimizations.
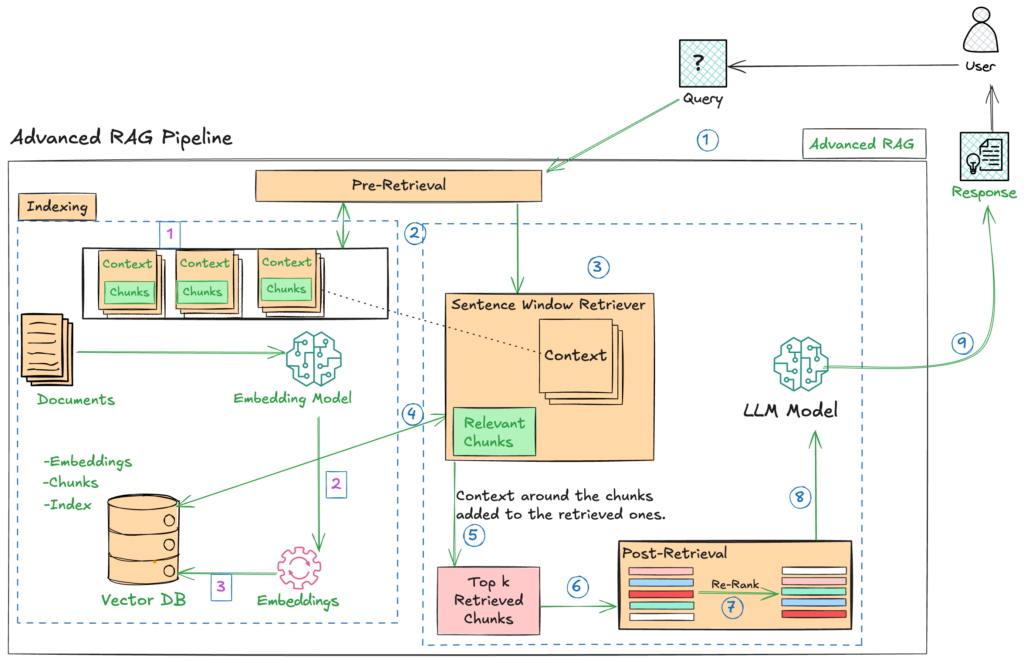
Overall Workflow:
The pipeline processes a user query by first converting it into an embedding, then using this embedding to search a vector database of document embeddings. Relevant chunks are retrieved, and their surrounding contexts are added. These are then – potentially after a post-retrieval reranking – passed to an LLM that generates a coherent response based on the selected and ordered context. This process combines the efficiency of vector search with the reasoning capabilities of LLMs to create a sophisticated information retrieval and response system. The use of a sentence window retriever and re-ranking improves the quality and accuracy of the response significantly compared to a simpler RAG pipeline.
Pre-retrieval
optimizations focus on optimizing data indexing and query processes to improve retrieval efficiency. Techniques such as sliding window, enhancing data granularity, adding metadata, and optimizing index structures are employed to store data in a way that facilitates efficient retrieval.
The retrieval stage aims to identify the most relevant context, typically using vector search to calculate the semantic similarity between the query and indexed data. As a result, most retrieval optimization techniques center around embedding models, including fine-tuning embedding models and dynamic embedding.
Additional processing of the retrieved context can help address issues like exceeding context window limits or introducing noise, which can hinder the focus on crucial information. Techniques like prompt compression and re-ranking are used as post-retrieval optimizations to refine the retrieved context.
Sentence Window Retrieval
In the Sentence Window Retrieval technique, a single sentence is fetched during retrieval, and a window of text surrounding the sentence is returned. The core concept behind Sentence Window Retrieval is the separation of embedding and synthesis processes, enabling more granular and targeted information retrieval. By focusing on individual sentences or smaller text units, rather than entire text chunks, this method allows for more precise embedding and storage in a vector database. This, in turn, facilitates more accurate similarity searches to identify the most relevant sentences for a given query. Moreover, Sentence Window Retrieval not only retrieves the relevant sentences but also includes the surrounding context, comprising the sentences preceding and following the target sentence. This expanded context window is then input into the language model for synthesis, ensuring that the generated response is coherent and complete.
Hybrid Search
Hybrid search is a search technique that integrates two or more search algorithms to enhance the relevance of search results. Typically, it combines traditional keyword-based search with modern vector search, although the specific algorithms used can vary. Historically, keyword-based search was the dominant approach for search engines, but the advent of machine learning algorithms and vector embeddings has enabled a new search paradigm: vector or semantic search. This allows for searches to be conducted across data semantically, rather than relying solely on keyword matches.
By combining keyword-based and vector searches into a hybrid search, the strengths of both techniques can be leveraged to improve the relevance of search results, particularly for text-search use cases. This approach allows for a more comprehensive and accurate search experience. Various vector databases, such as Qdrant, support hybrid search by combining search results from sparse and dense vectors.
Re-Ranking
In RAG, reranking is used to reorder and filter retrieved contexts, placing the most relevant ones first. This is necessary because semantic search may not always retrieve the most relevant information due to information loss during vector compression. Reranking helps improve recall performance by reordering the top items, even if a better retrieval model is used.
Reranking is done using re-rank models, which are cross-encoder models that take a document-query pair as input and output a combined relevance score. This allows users to sort documents by relevance for a given query. Various re-ranking models are available, including BAAI/bge-reranker-base, which I used in this post with SentenceTransformerRerank. SentenceTransformerRerank uses cross-encoders to re-order nodes, improving the overall effectiveness of RAG.
Benifits of RAG
The RAG approach offers several benefits, including:
Improved Accuracy: By retrieving relevant information from a knowledge base, RAG can provide more accurate and up-to-date responses.
Contextual Relevance: The retrieved information helps to ensure that the generated response is contextually relevant and takes into account the specific details of the query.
Scalability: RAG can handle large volumes of data and scale to meet the needs of complex applications.
Flexibility: The RAG approach can be adapted to various domains and applications, including question answering, text summarization, and chatbots.
Applications of RAG
Question Answering: RAG can be used to answer questions on a wide range of topics, from general knowledge to domain-specific questions.
RAG has a wide range of applications, including:
Text Summarization: RAG can be used to summarize long documents or articles, highlighting the key points and main ideas.
Chatbots: RAG can be used to power chatbots and virtual assistants, providing more accurate and contextually relevant responses to user queries.
Language Translation: RAG can be used to improve language translation, by retrieving relevant information from a knowledge base and using it to inform the translation process.
Real-World Examples of RAG
Virtual Assistants: Virtual assistants like Siri, Google Assistant, and Alexa use RAG to provide more accurate and contextually relevant responses to user queries.
Customer Service Chatbots: Customer service chatbots use RAG to provide more informative and engaging responses to customer inquiries.
Language Translation Apps: Language translation apps like Google Translate use RAG to improve the accuracy and fluency of translations.
News Summarization: News summarization apps use RAG to summarize long news articles, highlighting the key points and main ideas.
Conclusion
RAG is a powerful NLP technique that combines information retrieval and text generation to provide more accurate and relevant responses, with vast applications and potential to revolutionize language model interactions..