I hope you’ve gained a basic understanding of setting up a simple chatbot and Ollama ecosystem. In this blog, we’ll take it a step further by exploring document summarization concepts using a RAG-based application. To get started, we’ll need to cover the basics of RAG, and then we’ll dive into a practical example. In this example, we’ll learn how to summarize documents and engage in conversations with uploaded documents using RAG.
Let’s break it down:
- We’ll start with a brief introduction to RAG and its key concepts.
- Then, we’ll move on to a hands-on example where we’ll apply RAG to summarize documents and chat with uploaded documents.
- By the end of this blog, you’ll have a solid understanding of how to use RAG for document summarization and conversational AI.
Let’s get started and explore the power of RAG in document summarization and chatbots!
RAG and its key concepts
Installation & Dev Setup
For installation and code setup please refer previous blog.
We will implement a ‘Chat with Documents’ application using an Advanced RAG pipeline, leveraging embedding models, LLM, post-processing, and re-ranking models.
1. Tools used
- Ollama for running the LLMs locally. If you want to learn more about Ollama and how to get started with it locally, visit this article first.
- Lllama Model: Use
ollama listto check if it is installed on your system, or else use the commandollama pull llama3.2to download the latest default manifest of the model. - Qdrant: Vector database to store the PDF document’s vector embeddings.
- Flask: It is a micro web framework written in Python that allows easy develo pment of web applications. Flask is ideal for building small to medium-sized web applications, APIs, and web services. It’s known for its simplicity, flexibility, and ease of u
- URL routing
- Template engine
- WSGI web app framewor.
2. Ollama and Qdrant Setup
This setup is necessary to configure the LLM, Embedding models and vector stores, which will be utilized in the example below.
3.Implementation
Here is a high-level design diagram illustrating the architecture we aim to achieve as part of the DocuSum project.
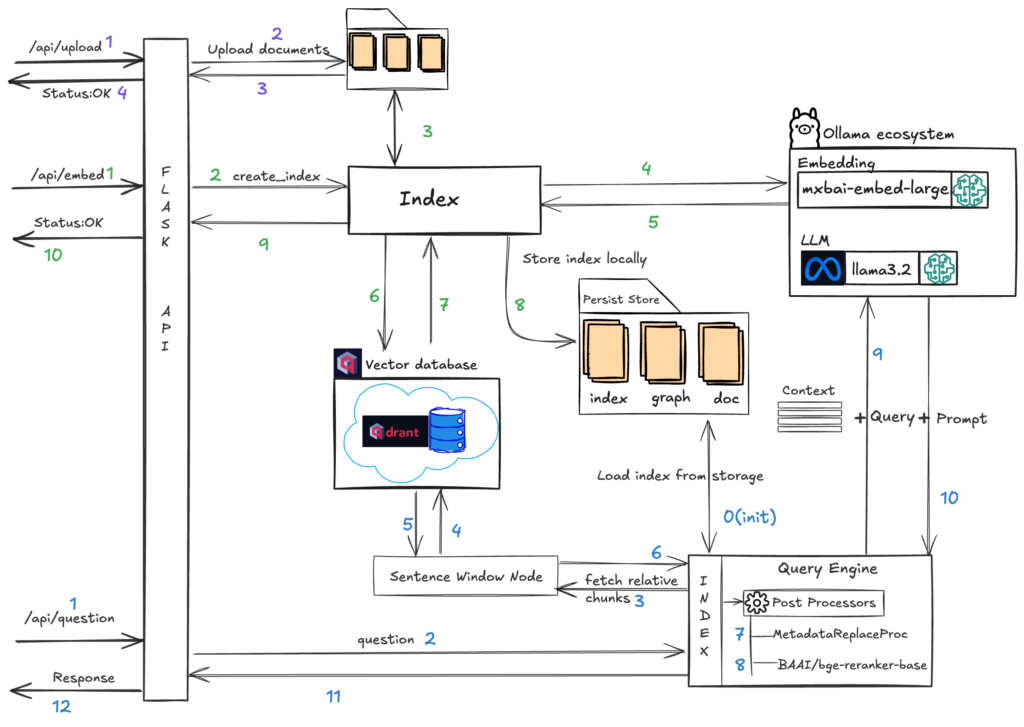
We will have three APIs to support the DocuSum functionalities, and the above diagram illustrates how these functionalities are handled within the system.
/api/upload
Upload documents into particular folder.
/api/embed
This API builds the index for the uploaded documents from the previous API. It first converts all documents into sentences using a sentence window parser, then calls the mxbai-embed-large embed model to create embeddings. The embeddings are stored in the Qdrant Vector store and the index is persisted locally using the persist directory. This index is used to build a Vector Index for the retrieval process and post-processing.
/api/question
This step initiates the query engine, built on the previously created index, to execute a hybrid search and retrieve relevant chunks from the vector store. The search results are then refined through metadata processing and re-ranking using the BAAI/bge-reranker-base model from Hugging Face, yielding the top k chunks. Ultimately, the chunks, prompt, and query are transmitted to the Large Language Model (LLM) – llama3.2 – to produce a response
Start coding…
Note: Since we’re using PyTorch dependencies, which currently support Python up to version 3.10, please ensure you’re using a compatible version. If you’re using a higher version, set up your environment with Python 3.10 using the following command
python3.10 -m venv docusum
source docusum/bin/activate- Navigate to the DocuSum project using the above command. Then, create a
requirements.txtfile and add the below content.
flask-cors
tiktoken
unstructured
Flask==2.0.1
llama-index
llama-index-vector-stores-qdrant
llama-index-llms-ollama
llama-index-embeddings-ollama
torch
sentence-transformers
Werkzeug==2.2.2
qdrant-client
fastembed- Create config.py
- Configure all required parameters in the config file by replacing the necessary configuration values.
- QDRANT_HOST, QDRANT_API_KEY, QDRANT_COLLECTION_NAME, OLLAMA_URL, LLM_MODEL,EMBED_MODEL, UPLOAD_FILE_PATH, INDEX_STORAGE_PATH
- Get the cofiguration values for QDRANT_HOST, QDRANT_API_KEY, QDRANT_COLLECTION_NAME, OLLAMA_URL, LLM_MODEL,EMBED_MODEL from the Ollama and Qdrant Setup.
- Configure all required parameters in the config file by replacing the necessary configuration values.
import os
# http api port
HTTP_PORT = os.getenv('HTTP_PORT', 7654)
#ollama
OLLAMA_URL= os.getenv('OLLAMA_URL','http://localhost:11434')
LLM_MODEL = os.getenv('LLM_MODEL','llama3.2')
EMBED_MODEL = os.getenv('EMBED_MODEL','mxbai-embed-large:latest')
# qdrant vector store config
#Replace this url with Qdrant actual url
QDRANT_HOST = os.getenv('QDRANT_URL','https://XXXXXXXX.us-west-2-0.aws.cloud.qdrant.io:6333')
#Replace this url with Qdrant API KEY
QDRANT_API_KEY = os.getenv('QDRANT_API_KEY','eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.XXXXXXXXXXXXXXXXXX')
QDRANT_COLLECTION_NAME = os.getenv('QDRANT_COLLECTION_NAME','advrag3')
UPLOAD_FILE_PATH = os.getenv('UPLOAD_FILE_PATH','XXXXX/work/file_storage')
INDEX_STORAGE_PATH = os.getenv('INDEX_STORAGE_PATH','XXXXX/work/index_storage')

- Create api.py
- We will have three routes to support upload, embed, and chat functionalities:
/api/upload: Handles document uploads to the configured folder./api/embed: Internally calls thereload_indexmethod from theappmodule to create embeddings and index./api/question: Internally calls thechatmethod to process the query and generate a response.”
from flask import Flask
from flask import jsonify
from flask import request
from flask_cors import CORS
import logging
import sys
from app import *
from config import *
app = Flask(__name__)
CORS(app)
logging.basicConfig(stream=sys.stdout, level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
@app.route('/api/embed', methods=['GET'])
def createEmbed():
if request.method == "GET":
load_index()
return jsonify({'status':'OK','message':'Created embeddings successfully!'}),200
@app.route('/api/upload', methods=['POST'])
def upload():
if request.method == "POST":
files = request.files.getlist("file")
for file in files:
file.save(os.path.join(f"{UPLOAD_FILE_PATH}", file.filename))
return jsonify({'status':'OK','message':'File(s) uploaded successfully!'}),200
@app.route('/api/question', methods=['POST'])
def post_question():
json = request.get_json(silent=True)
question = json['question']
user_id = json['user_id']
logging.info("post question `%s` for user `%s`", question, user_id)
resp = chat(question, user_id)
data = jsonify({'answer':resp})
return data, 200
if __name__ == '__main__':
init_llm()
init_index()
init_query_engine()
app.run(host='0.0.0.0', port=HTTP_PORT, debug=True)
- Initinatlizing init_llm(), init_index() and init_query_engine() methos in __main__ top leve code code environment from app module.
- Create app.py
- init_llm(): Initialize Ollama llm and embedding models
def init_llm():llm=Ollama(base_url=f"{OLLAMA_URL}", model=f"{LLM_MODEL}", temperature=0.8, request_timeout=300,system_prompt="You are an agent who consider the context passed ""in, to answer any questions dont consider your prior ""knowledge to answer and if you dont find the answer ""please respond that you dont know.")
embed_model=OllamaEmbedding(base_url=f"{OLLAMA_URL}", model_name=f"{EMBED_MODEL}")Settings.llm=llmSettings.embed_model=embed_model- init_index(): This method initializes the index using the configured persistent storage. On the first run, the persistent folder will be empty, and the
load_index()method will be called to build the index, which will then be stored in the persistent store.
def init_index():
global index
global vector_store
# create qdrant client
qdrant_client = QdrantClient(
url=f"{QDRANT_HOST}",
api_key=f"{QDRANT_API_KEY}",
)
# qdrant vector store with enabling hybrid search
vector_store = QdrantVectorStore(
collection_name=f"{QDRANT_COLLECTION_NAME}",
client=qdrant_client,
enable_hybrid=True,
batch_size=20
)
upload_files = len(os.listdir(f"{UPLOAD_FILE_PATH}"))
if upload_files > 1:
index_storage_files = len(os.listdir(f"{INDEX_STORAGE_PATH}"))
if index_storage_files > 1:
new_storage_context = StorageContext.from_defaults( vector_store=vector_store, persist_dir=f"{INDEX_STORAGE_PATH}")
index = load_index_from_storage(new_storage_context)
else:
load_index()
- load_index(): This method loads files from the upload path, converts them into documents, and creates a vector store using the sentence window node parser and embed model. This method is responsible for creating embeddings, storing them in the vector store, and ultimately creating an index that is persisted to the index storage path.
def load_index():
global vector_store
reader = SimpleDirectoryReader(input_dir=f"{UPLOAD_FILE_PATH}", recursive=True)
documents = reader.load_data()
logging.info("index creating with `%d` documents", len(documents))
# create large document with documents for better text balancing
document = Document(text="\n\n".join([doc.text for doc in documents]))
# sentece window node parser
# window_size = 3, the resulting window will be three sentences long
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
# storage context and service context
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# initialize vector store index with qdrant
index = VectorStoreIndex.from_documents(
[document],
#service_context=service_context,
storage_context=storage_context,
embed_model=Settings.embed_model,
node_parser=node_parser,
)
index.storage_context.persist(persist_dir=f"{INDEX_STORAGE_PATH}")
- init_query_engine(): Loads the index from the local index storage path, applies the metadata replace post processorand re-rank nodes, and creates a query engine to enable user chat functionality.
def init_query_engine():
global query_engine
global index
# after retrieval, we need to replace the sentence with the entire window from the metadata by defining a
# MetadataReplacementPostProcessor and using it in the list of node_postprocessors
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
# re-ranker with BAAI/bge-reranker-base model
rerank = SentenceTransformerRerank(
top_n=2,
model="BAAI/bge-reranker-base"
)
#reranker = LLMRerank(choice_batch_size=5, top_n=5)
#reranked_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)
new_storage_context = StorageContext.from_defaults( vector_store=vector_store, persist_dir=f"{INDEX_STORAGE_PATH}")
index = load_index_from_storage(new_storage_context)
# similarity_top_k configure the retriever to return the top 3 most similar documents, the default value of similarity_top_k is 2
# use meta data post processor and re-ranker as post processors
query_engine = index.as_query_engine(
similarity_top_k=3,
node_postprocessors=[postproc, rerank],
)
- chat():
def chat(input_question, user): global query_engine
response = query_engine.query(input_question) logging.info("response from llm - %s", response)
# view sentece window retrieval window and origianl text logging.info("sentence window retrieval window - %s", response.source_nodes[0].node) logging.info("sentence window retrieval orginal_text - %s", response.source_nodes)
return response.response
- Install the dependencies using the following command
pip install -r requirements.txt- Before running
app.py, ensure that the LLM and Embed Model are running in the Ollama ecosystem and that the Qdrant vector store is set up
- Once the above steps are complete, run
api.pyusing the following command
python api.py- If you encounter issues with
requirements.txt, run the following commands to install dependencies.
pip install flask-cors
pip install tiktoken
pip install unstructured
pip install Flask==2.0.1
pip install llama-index
pip install llama-index-vector-stores-qdrant
pip install llama-index-llms-ollama
pip install llama-index-embeddings-ollama
pip install torch
pip install -U sentence-transformers
pip install qdrant-client
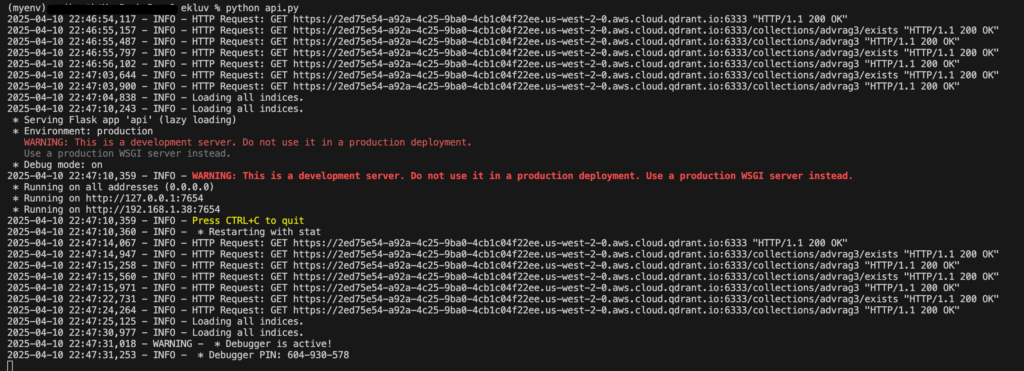
pip install Werkzeug==2.2.2- Below is the output after a successful run
- The server will run on
http://localhost:7654. The available APIs are- /api/upload
curl --location 'http://localhost:7654/api/upload' \
--form 'file=@"/path/to/file"'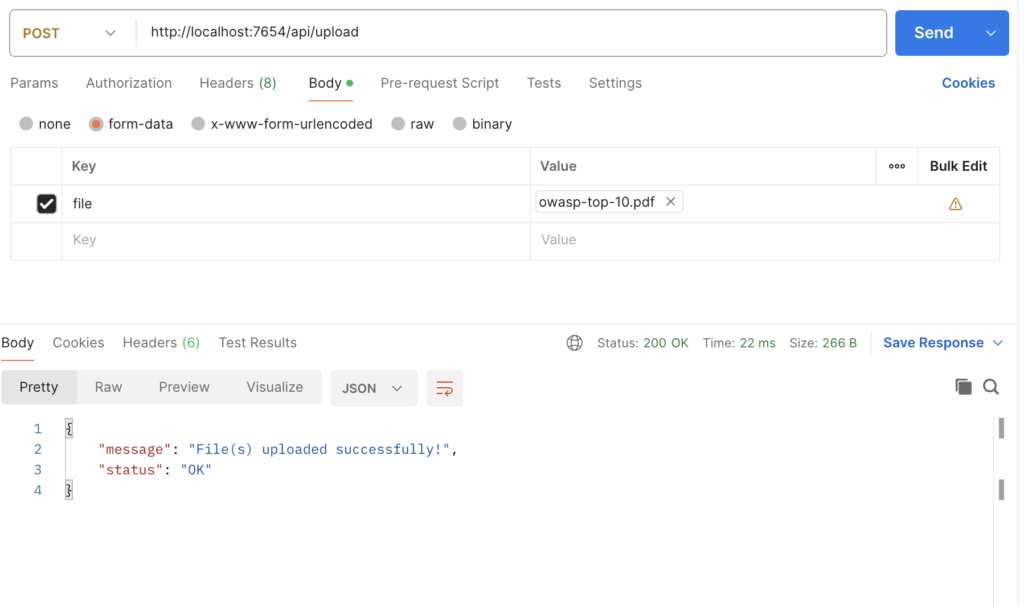
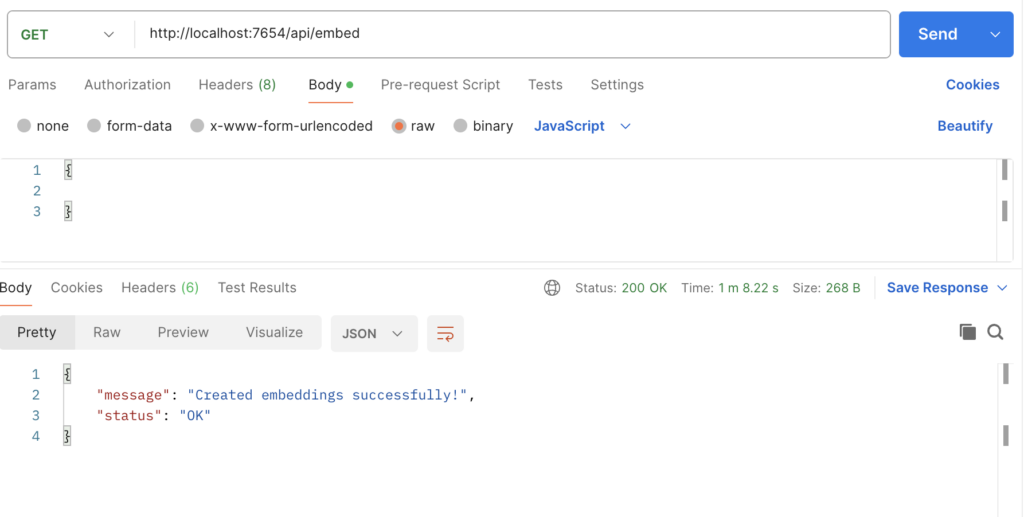
- /api/embed
curl --location --request GET 'http://localhost:7654/api/embed' \
--header 'Content-Type: application/javascript' \
--data '{
}'
- /api/question
curl --location 'http://localhost:7654/api/question' \
--header 'Content-Type: application/json' \
--data '{
"question": "List out OWASP top 10 ",
"user_id": "docusum"
}'- Example 1
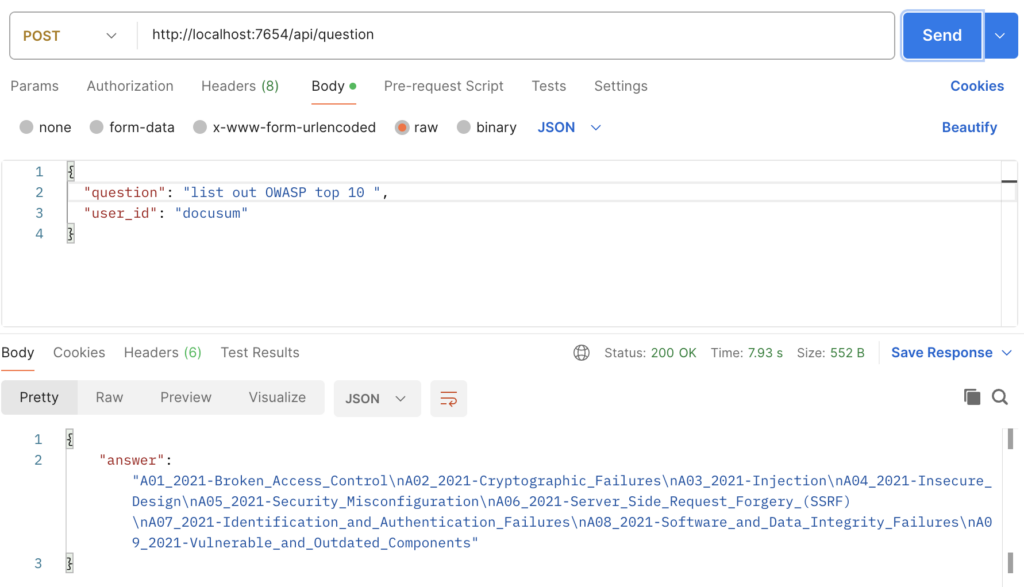
- Example 2
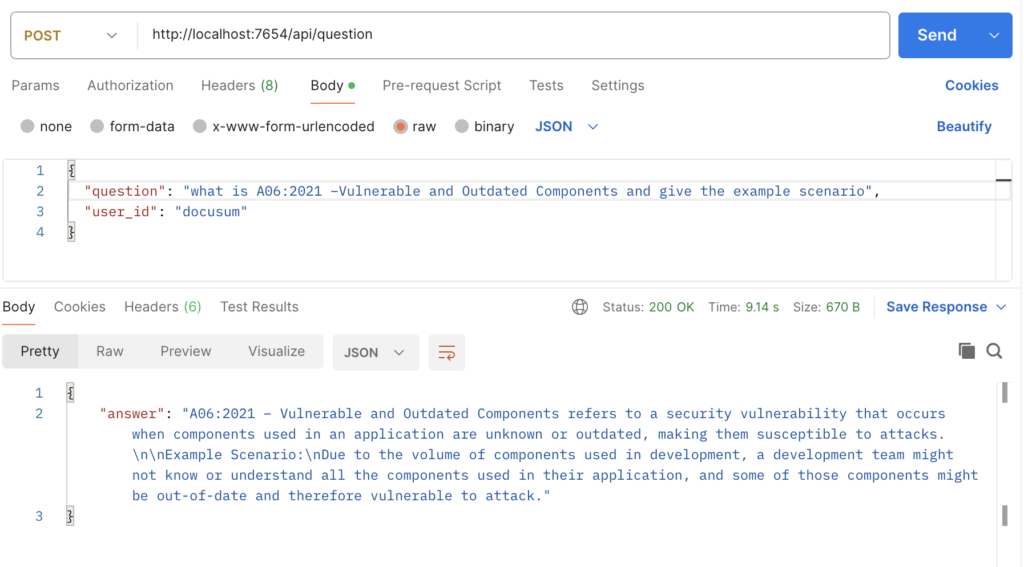
- Context from the PDF

- Full Code
Conclusion:
In this post, we’ve explored advanced RAG pipeline setup using sentence window node and hybrid search when querying vector stores, as well as post-processors to refine context further using metadata post-processing and re-ranking. Additionally, we’ve covered setting up the Ollama ecosystem to run LLM and Embed locally, and Qdrant vector store from the cloud. Hope this blog helps to provide a better understanding of Advanced RAG concepts
Happy Coding! 🙂
References
- https://lightning.ai/lightning-ai/studios/document-summarization-chat-rag-application?section=featured
- https://medium.com/rahasak/production-ready-advanced-rag-optimization-with-llama-index-and-qdrant-vector-database-23ad6427b20a
- https://akanshasaxena.com/post/documentor-rag-app/
- https://akash-mathur.medium.com/advanced-rag-enhancing-retrieval-efficiency-through-evaluating-reranker-models-using-llamaindex-3f104f24607e
- https://medium.com/@govindarajpriyanthan/advanced-rag-building-and-evaluating-a-sentence-window-retriever-setup-using-llamaindex-and-67bcab2d241e